Various Summarization Functions
Introduction
We have covered basic summarization operation here.
We will now explore some common summarization functions.
Procedure
We will be working with a custom dataframe.
# package for creating dataframe
library(tibble)
# tibble or dataframe
df <- tibble(numeric_col = as.integer(c(1:10)),
categorical_col = c("A","B","C","D","E","F","G","H","I","J")
)
View(df)Few rows of the data are:
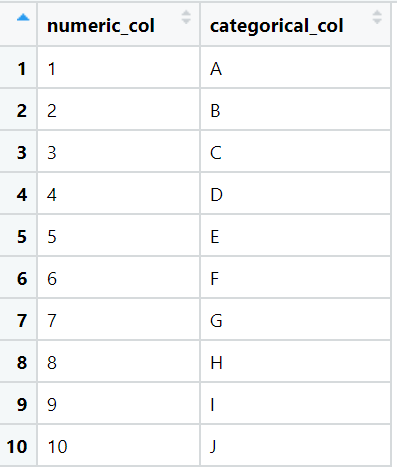
-
Compute Mean
We will compute mean for the numerical column.
# refer procedure for definition of df
library(dplyr)
# compute mean for numeric_col
result <- summarize(df, mean=mean(numeric_col))
View(result)The output of above code is:
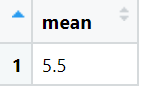
-
Compute Median
We will compute median for the numerical column.
# refer procedure for definition of df
library(dplyr)
# compute median for numeric_col
result <- summarize(df, median = median(numeric_col))
View(result)The output of above code is:

-
Compute Standard Deviation
We will compute standard deviation for the numerical column. The standard deviation is computed using the squared distances formula.
# refer procedure for definition of df
library(dplyr)
# compute standard deviation for numeric_col
result <- summarize(df, `standard deviation` = sd(numeric_col))
View(result)The output of above code is:
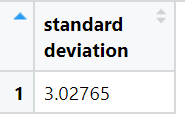
It means from the mean the values on average spread by 3.02765.
-
Compute Interquartile Range
We will compute interquartile range for the numerical column.
# refer procedure for definition of df
library(dplyr)
# compute interquartile range for numeric_col
result <- summarize(df, `interquartile range` = IQR(numeric_col))
View(result)The output of above code is:

-
Compute Median absolute deviation
We will compute median absolute deviation for the numerical column.
# refer procedure section for definition of df
library(dplyr)
# compute median absolute deviation for numeric_col
result <- summarize(df, `median absolute deviation` = mad(numeric_col))
View(result)The output of above code is:

-
Find Minimum
We will find minimum value for the numeric column as well as the categorical column. For categorical column the minimum is found by using the Lexicographical Order.
# refer procedure section for definition of df
library(dplyr)
# find min for numeric_col and categorical_col
result <- summarize(df, `minimum_numeric` = min(numeric_col),
`minimum_categorical` = min(categorical_col))
View(result)The output of above code is:

-
Find Quantile
We will compute the 25th quantile and the 50th quantile for numerical column.
# refer procedure section for definition of df
library(dplyr)
# find 25th and 50th quantile for numeric_col
result <- summarize(df, `25th Quantile` = quantile(numeric_col,0.25),`50th Quantile or Median` = quantile(numeric_col,0.5))
View(result)The output of above code is:
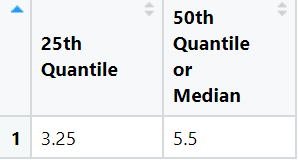
-
Find Maximum
We will find maximum value for the numeric column as well as the categorical column. For categorical column the maximum is found by using the Lexicographical Order.
# refer procedure section for definition of df
library(dplyr)
# find max for numeric_col and categorical_col
result <- summarize(df, `maximum_numeric` = max(numeric_col),
`maximum_categorical` = max(categorical_col))
View(result)The output of above code is:

-
Find First
We will find first value for the numeric column as well as the categorical column. For categorical column the first value is found by using the Lexicographical Order.
# refer procedure section for definition of df
library(dplyr)
# find first for numeric_col and categorical_col
result <- summarize(df,
`first_numeric` = first(numeric_col),
`first_categorical` = first(categorical_col))
View(result)The output of above code is:
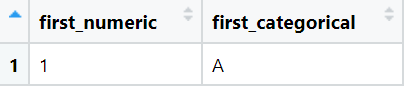
-
Find nth
We will find nth value for the numeric column as well as the categorical column. For categorical column the nth value is found by using the Lexicographical Order.
# refer procedure section for definition of df
library(dplyr)
# find 3rd value for numeric_col and categorical_col
result <- summarize(df,
`3rd_numeric` = nth(numeric_col,3),
`3rd_categorical` = nth(categorical_col,3))
View(result)The output of above code is:
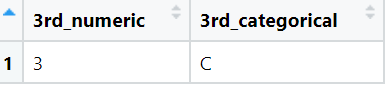
-
Find Last
We will find last value for the numeric column as well as the categorical column. For categorical column the last value is found by using the Lexicographical Order.
# refer procedure section for definition of df
library(dplyr)
# find last for numeric_col and categorical_col
result <- summarize(df,
`last_numeric` = last(numeric_col),
`last_categorical` = last(categorical_col))
View(result)The output of above code is:
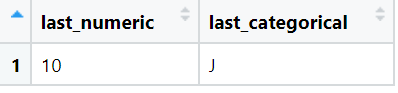
-
Count
We will count the number of rows in df dataframe.
# refer procedure section for definition of df
library(dplyr)
# count rows in df
result <- summarize(df, `row count` = n())
View(result)The output of above code is:
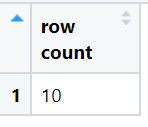
-
Count unique
We will count the number of unique or distinct values in numeric_col and categorical_col.
# refer procedure section for definition of df
library(dplyr)
# count unique values in numeric_col and categorical_col
result <- summarize(df,
`numeric_col unique` = n_distinct(numeric_col),
`categorical_col unique` = n_distinct(categorical_col)
)
View(result)The output of above code is:
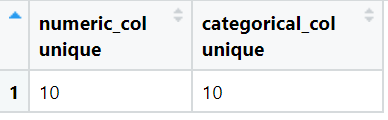
-
Count non-missing
We will count the number of non-missing values in numeric_col and categorical_col. Non-missing values are NA’s.
# refer procedure section for definition of df
library(dplyr)
# count non-missing values in numeric_col and categorical_col
result <- summarize(df,
`numeric_col non-missing values` = sum(!is.na(numeric_col)),
`categorical_col non-missing values` = sum(!is.na(categorical_col))
)
View(result)The output of above code is:

Conclusion
Thus we have successfully explored various summarization functions.
References
- https://r4ds.had.co.nz/